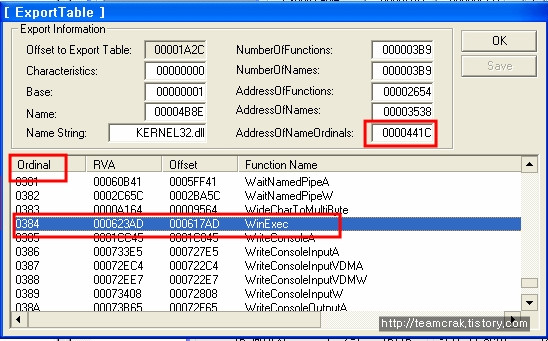
라운드 키 생성과정
위에서 나온 값들을 이용하여 암호화와 복호화 라운드 키(eki, dki)를 생성합니다.
라운드 수는 x비트일 경우 (x+256)/32 라운드 수. (각각 12,14,16 라운드)
마지막 라운드에 키 덧셈 계층이 두 번 있으므로 13,15,17 개의 라운드 키 생성.
라운드 암호화 키 생성 공식
ek1 = (W0) XOR (W1>>>19), ek2 = (W1) XOR (W2>>>19)
ek3 = (W2) XOR (W3>>>19), ek4 = (W3) XOR (W0>>>19)
ek5 = (W0) XOR (W1>>>31), ek6 = (W1) XOR (W2>>>31)
ek7 = (W2) XOR (W3>>>31), ek8 = (W3) XOR (W0>>>31)
ek9 = (W0) XOR (W1>>>61), ek10 = (W1) XOR (W2>>>61)
ek11 = (W2) XOR (W3>>>61), ek12 = (W3) XOR (W0>>>61)
ek13 = (W0) XOR (W1>>>31), ek14 = (W1) XOR (W2>>>31)
ek15 = (W2) XOR (W3>>>31), ek16 = (W3) XOR (W0>>>31)
ek17 = (W2) XOR (W3>>>19)
복호화 라운드 키 생성 공식
dk1 = ekn+1, dk2 = A(ekn), dk3 = A(ekn-1), …. , dkn = A(ek2), dkn+1 = ek1
3. 소스코드 분석
현재 국가보안기술연구소 홈페이지에 공개되어 있는 소스는 테스트 용도로써 치환, 확산, 키 확장 등의 원리를 이해하는데 도움이 되었으며, 본 소스코드 암호화 이후의 결과가 정상적으로 이루어지는가와 암호화 복호화가 잘 이루어 지는가에 대한 확인을 그 목적으로 하고 있습니다.
1) 중요 함수
확산 계층 함수, 암호화 키 생성 함수, 복호화 키 생성 함수, 라운드 키 생성함수, 치환 및 암호화 함수
2) 확산 계층 함수 – DL(const Byte *i, Byte *o)
확산 계층 함수 : DL함수(FO, Fe 부분을 담당)
입력값 : input 배열과 output 배열 선언 >> DL(const Byte *I, Byte *O)
확산과정을 거치기 위한 임의의 공간 T 선언 >> Byte T;
일정한 규칙에 따른 4개의 인자 값을 XOR 계산
출력값 output 배열에 T값과 해당되는 인자 값에 키 값과 XOR 한 값을 저장합니다.
소스코드 일부분:
T = i[ 3] ^ i[ 4] ^ i[ 9] ^ i[14]; // T 값에 XOR 결과값 입력
o[ 0] = i[ 6] ^ i[ 8] ^ i[13] ^ T; // T와 각각의 output 값 생성
o[ 5] = i[ 1] ^ i[10] ^ i[15] ^ T;
o[11] = i[ 2] ^ i[ 7] ^ i[12] ^ T;
o[14] = i[ 0] ^ i[ 5] ^ i[11] ^ T;
3) 암호화 키 생성 함수 – EncKeySetup(const Byte *w0, Byte *e, int keyBits)
입력값은 첫번째 라운드 키 w0, 암호화된 라운드 키 e, 키 비트 KeyBits
임시 저장장소 t[16], 라운드 키 w1[16], w2[16], w3[16]
q = Fesitel 암호 라운드 키 세가지 구분(0 = C1, 1 = C2, 2 = C3)
int EncKeySetup(const Byte *w0, Byte *e, int keyBits) {
int i, R=(keyBits+256)/32, q;
Byte t[16], w1[16], w2[16], w3[16];
q = (keyBits - 128) / 64; // Feistel 암호 라운드 키 C1=0, C2=1, C3=2
for (i = 0; i < 16; i++) t[i] = S[ i % 4][KRK[q][i ] ^ w0[i]];
// S-box 에서 x값은 S-box s1,s2,s1-1,s2-1 4가지가 한번씩 돌아가면서 입력되도록 체크
// KRK[q][i]^w0[i] Feistel 암호 라운드 키와 암호화 라운드 키를 한 비트씩 XOR 연산
DL (t, w1); // 확산함수를 통한 w1값 결정
if (R==14)
for (i = 0; i < 8; i++) w1[i] ^= w0[16+i];
else if (R==16)
for (i = 0; i < 16; i++) w1[i] ^= w0[16+i];
q = (q==2)? 0 : (q+1);
for (i = 0; i < 16; i++) t[i] = S[(2 + i) % 4][KRK[q][i] ^ w1[i]];
DL (t, w2); // 확산함수를 통한 w2 결정
for (i = 0; i < 16; i++) w2[i] ^= w0[i]; //w2와 w0 XOR 연산
q = (q==2)? 0 : (q+1);
// Feistel 암호화 라운드 키를 키 비트수에 따라 하나씩 밀려서 쓰기 때문에 이와 같은 방법을 선택. 2가 되면 0으로 돌리고, 2가 되기 전까지는 +1 을 함.
for (i = 0; i < 16; i++) t[i] = S[ i % 4][KRK[q][i] ^ w2[i]];
DL (t, w3); //
for (i = 0; i < 16; i++) w3[i] ^= w1[i];
for (i = 0; i < 16*(R+1); i++) e[i] = 0; //e[i] 값을 초기화
아래의 RotXOR 함수는 아래에서 따로 설명하겠습니다.
RotXOR (w0, 0, e ); RotXOR (w1, 19, e );
RotXOR (w1, 0, e + 16); RotXOR (w2, 19, e + 16);
RotXOR (w2, 0, e + 32); RotXOR (w3, 19, e + 32);
RotXOR (w3, 0, e + 48); RotXOR (w0, 19, e + 48);
RotXOR (w0, 0, e + 64); RotXOR (w1, 31, e + 64);
RotXOR (w1, 0, e + 80); RotXOR (w2, 31, e + 80);
RotXOR (w2, 0, e + 96); RotXOR (w3, 31, e + 96);
RotXOR (w3, 0, e + 112); RotXOR (w0, 31, e + 112);
RotXOR (w0, 0, e + 128); RotXOR (w1, 67, e + 128);
RotXOR (w1, 0, e + 144); RotXOR (w2, 67, e + 144);
RotXOR (w2, 0, e + 160); RotXOR (w3, 67, e + 160);
RotXOR (w3, 0, e + 176); RotXOR (w0, 67, e + 176);
RotXOR (w0, 0, e + 192); RotXOR (w1, 97, e + 192);
if (R > 12) {
RotXOR (w1, 0, e + 208); RotXOR (w2, 97, e + 208);
RotXOR (w2, 0, e + 224); RotXOR (w3, 97, e + 224);
}
if (R > 14) {
RotXOR (w3, 0, e + 240); RotXOR (w0, 97, e + 240);
RotXOR (w0, 0, e + 256); RotXOR (w1, 109, e + 256);
}
return R;
}
4) 복호화 키 생성 함수 – DecKeySetup(const Byte *w0, Byte *d, int keyBits)
w0 : 암호화 라운드 첫번째 값, d : 복호화 라운드 키, KeyBits : 키 비트 수
int DecKeySetup(const Byte *w0, Byte *d, int keyBits) {
int i, j, R;
Byte t[16];
R=EncKeySetup(w0, d, keyBits); // 암호화 라운드 키 생성
// d값에는 암호화된 라운드 키가 입력되어 있음.
for (j = 0; j < 16; j++){
t[j] = d[j];
d[j] = d[16*R + j]; // 암호화된 라운드 키를 치환하는 부분
d[16*R + j] = t[j];
// 치환을 통한 복호화 라운드 키 생성
}
for (i = 1; i <= R/2; i++){
DL (d + i*16, t);
DL (d + (R-i)*16, d + i*16);
for (j = 0; j < 16; j++) d[(R-i)*16 + j] = t[j];
}
// 확산 및 치환 단계를 처리하는 부분
return R;
}
5) 라운드 키 생성 함수 – RotXOR(const Byte *s, int n, Byte *t)
s : 라운드 키로 얻은 네, 개의 비트 값, n : 쉬프트 비트 수, 암호화 키 배열 eKi값
void RotXOR (const Byte *s, int n, Byte *t)
{
int i, q;
q = n/8; n %= 8;
for (i = 0; i < 16; i++) {
t[(q+i) % 16] ^= (s[i] >> n);
if (n != 0) t[(q+i+1) % 16] ^= (s[i] << (8-n));
}
// 두 가지 경우의 수로 나누어서 비트 쉬프트 연산과 XOR 연산 수행
}
6) 치환 및 암호화 함수 – Crypt(const Byte *p, int R, const Byte *e, Byte *c)
P : 평문 바이너리, R : 라운드 수, e :
void Crypt(const Byte *p, int R, const Byte *e, Byte *c)
{
int i, j;
Byte t[16];
for (j = 0; j < 16; j++) c[j] = p[j];
for (i = 0; i < R/2; i++) // 라운드의 절반만 루프를 돌린다 하지만 내부에 두 번씩(S라는 함수와 역함수S-1 교대로) 돌게 되어있음.
{
for (j = 0; j < 16; j++) t[j] = S[ j % 4][e[j] ^ c[j]];
DL(t, c); e += 16;
for (j = 0; j < 16; j++) t[j] = S[(2 + j) % 4][e[j] ^ c[j]];
// S-box 교대로 적용하기 위해 +2가 적용됨. 나머지는 같음.
DL(t, c); e += 16;
}
DL(c, t);
for (j = 0; j < 16; j++) c[j] = e[j] ^ t[j]; // 최종 라운드에서 한번 더 ekn+1 키 교환
}
IV. 마무리
1. 끝맺으며
ARIA 알고리즘을 분석해보겠다고 덥썩 덤벼들긴 했지만, 수학적인 능력과 암호학에 대한 이해, 분석을 위해 주어진 시간(이 부분은 능력에 비례하는 것일지도 모르겠다.)이 부족하여 결국에는 알고리즘에 대한 소개와 명세어의 요약정도에 그친 것 같아 아쉬웠습니다. 블로그들을 검색해보니 이보다 더 훌륭한 글들이 많아서 오픈해야 하나 참 많이 망설였습니다.
실제 우리 주변에서 SEED와 함께 쓰일 암호 알고리즘으로써 정부기관을 축으로 사용될 것으로 예측되고, 여러 학회에서 발표된 자료에 안전성이 어느정도는 입증(SEED보다 안전?)된 것도 같습니다. 실제로 이 부분에 대한 증명에 관한 자료도 존재하였습니다. 향후에, 이 부분에 대한 증명을 스스로 해보고 싶은 욕구도 생기더군요.
부족한 글이지만, 여기까지 읽어주셨다면 감사하다고 말씀드리고 싶네요. 읽으시느라 수고하셨습니다.
2. 참고문헌
1) 안전성과 효율성을 갖춘 128-비트 블록 암호 알고리즘 설계 및 분석 /임웅택 – 국회전자도서관 / 서울 : 숭실대 대학원, 200502
※참고한 내용 : ARIA 에 대한 소개 글에 포함된 그림 사용.
2) ARIA 명세서 및 소스코드 공개 : 국가정보원 IT 보안인증사무국 페이지 :
http://www.kecs.go.kr/pw_certified/aria_open.jsp
3. 용어설명
1) ARIA : Academy, Research Institute, Agency 의 약어. 학연관이 공동으로 개발함을 함축.
2) Involution 구조 : 암호화 과정과 복호화 과정이 같은 구조
3) S-box : 비선형 치환 테이블로 바이트 치환에 사용됨.
4) SPN 구조 : Substitute-Permutation-Network 구조로 S-box와 확산 함수가 반복적으로 사용되는 구조
5) Feistel 구조 : 데이터를 두 블록으로 나누어 좌우 부분에 교대로 비선형 변환을 적용시키는 구조.
6) 대칭키 암호 : 암복호화 키가 같은 암호
7) 라운드 키 : 암호키로부터 키 확장을 통하여 생성되는 값들로 암호화 및 복호화 상태에 적용됨.
8) 라운드 함수 : 블록 암호의 각 라운드에서 사용되는 함수
9) 복호화 : 암호키를 이용하여 암호문을 평문으로 바꾸는 일련의 변환들
10) 블록 : 입력, 상태, 출력, 라운드 키를 구성하는 비트 열로 열의 길이는 포함하는 비트 수를 표시, 블록은 바이트의 배열로도 해석 가능.
11) 블록 암호 : 고정된 길이의 평문 블록을 고정된 길이의 암호문 블록으로 변환하는 함수
12 ) 상태 (state) : 암호화, 복호화 과정의 중간 값
13) 아핀 변환(Affine Transformation) : 행렬의 곱과 벡터의 합이 순차적으로 구성된 변환
14) 키 확장 : 암호 키로부터 라운드 키들을 생성하는 과정
15) MK : 암호 키
16) XOR : 배타적 논리합 연산
17) A <<< k : A의 각 비트를 왼쪽으로 k비트씩 순환이동.
18) A >>> k : A의 각 비트를 오른쪽으로 k비트씩 순환이동.